What Is a Dataset?
A dataset is a collection of related documents, typically grouped by source. Datasets are created automatically when you sync a data source, grouped by thesource field in your vector database.
Product Documentation
All docs from your product guide
Support Articles
Knowledge base articles
Engineering Wiki
Internal technical docs
API Reference
API documentation
Viewing Dataset Analytics
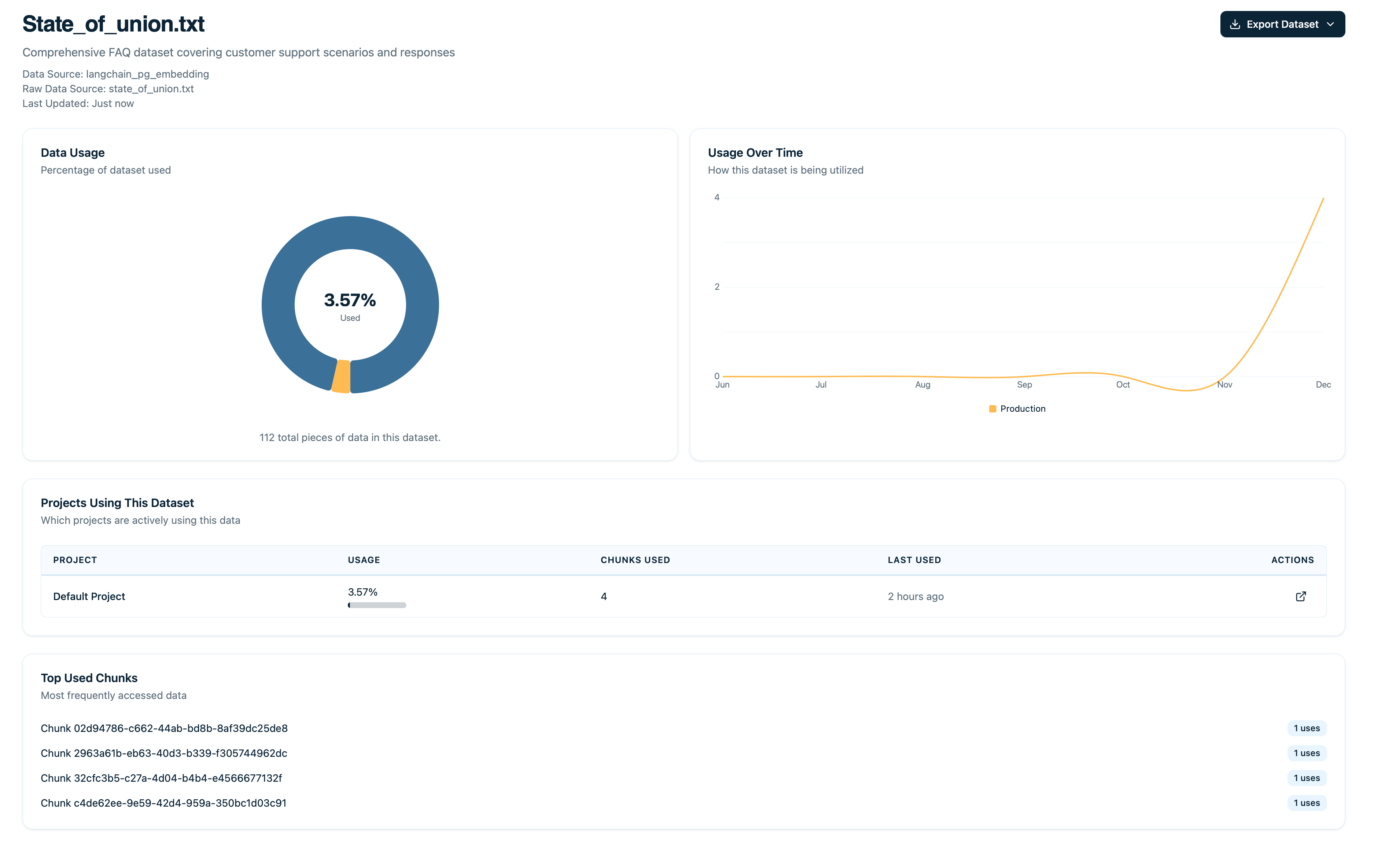
Dataset Overview Metrics
Total Documents
How many documents are in this dataset.
Total Retrievals
How many times any document in this dataset was retrieved.
| Dataset Size | Document Count | Meaning |
|---|---|---|
| Large | 1000+ | Comprehensive coverage |
| Medium | 100-1000 | Moderate coverage |
| Small | < 100 | Focused or incomplete coverage |
| Activity Level | Meaning |
|---|---|
| High | Core dataset, frequently referenced |
| Medium | Regularly used |
| Low | Rarely needed |
Usage Rate
Percentage of documents that have been retrieved at least once.| Usage Rate | Meaning |
|---|---|
| > 50% | Excellent - Most documents are useful |
| 30-50% | Good - Majority of docs are relevant |
| 10-30% | Fair - Many unused documents |
| < 10% | Poor - Dataset mostly unused |
Average Relevance Coming Soon
Mean relevance score across all retrievals in this dataset.| Score | Quality |
|---|---|
| > 0.75 | Excellent - Strong semantic matches |
| 0.60-0.75 | Good - Mostly relevant |
| 0.45-0.60 | Fair - Some weak matches |
| < 0.45 | Poor - Retrieval quality issues |
Document Distribution
See how retrievals are distributed across documents to understand which content is most valuable and which might need attention.Top Documents
The most-retrieved documents in this dataset.| Information Shown | Description |
|---|---|
| Document name | Title of the document |
| Retrieval count | Number of times retrieved |
| Percentage of total retrievals | Share of all retrievals in this dataset |
Unused Documents
Documents with zero retrievals that may need attention.| Information Shown | Description |
|---|---|
| Document name | Title of the document |
| Last updated | When it was last modified |
| Reason | Why it might be unused (if determinable) |
Click on any unused document to read its content, check if it should be deleted or improved, and verify embeddings are working.
Retrieval Distribution Graph Coming Soon
Histogram showing how many documents fall into each retrieval count bucket.| Bucket | Retrieval Count | Example Document Count |
|---|---|---|
| Bucket 0 | 0 retrievals | 45 documents |
| Bucket 1 | 1-10 retrievals | 30 documents |
| Bucket 2 | 11-50 retrievals | 15 documents |
| Bucket 3 | 51-100 retrievals | 8 documents |
| Bucket 4 | 100+ retrievals | 2 documents |
Highly concentrated retrievals? If top 10 documents account for >80% of retrievals:
| Aspect | Interpretation |
|---|---|
| Good | You know which docs are critical |
| Bad | Rest of dataset might be irrelevant |
Usage Trends Over Time
Graph showing retrieval activity for this dataset over time: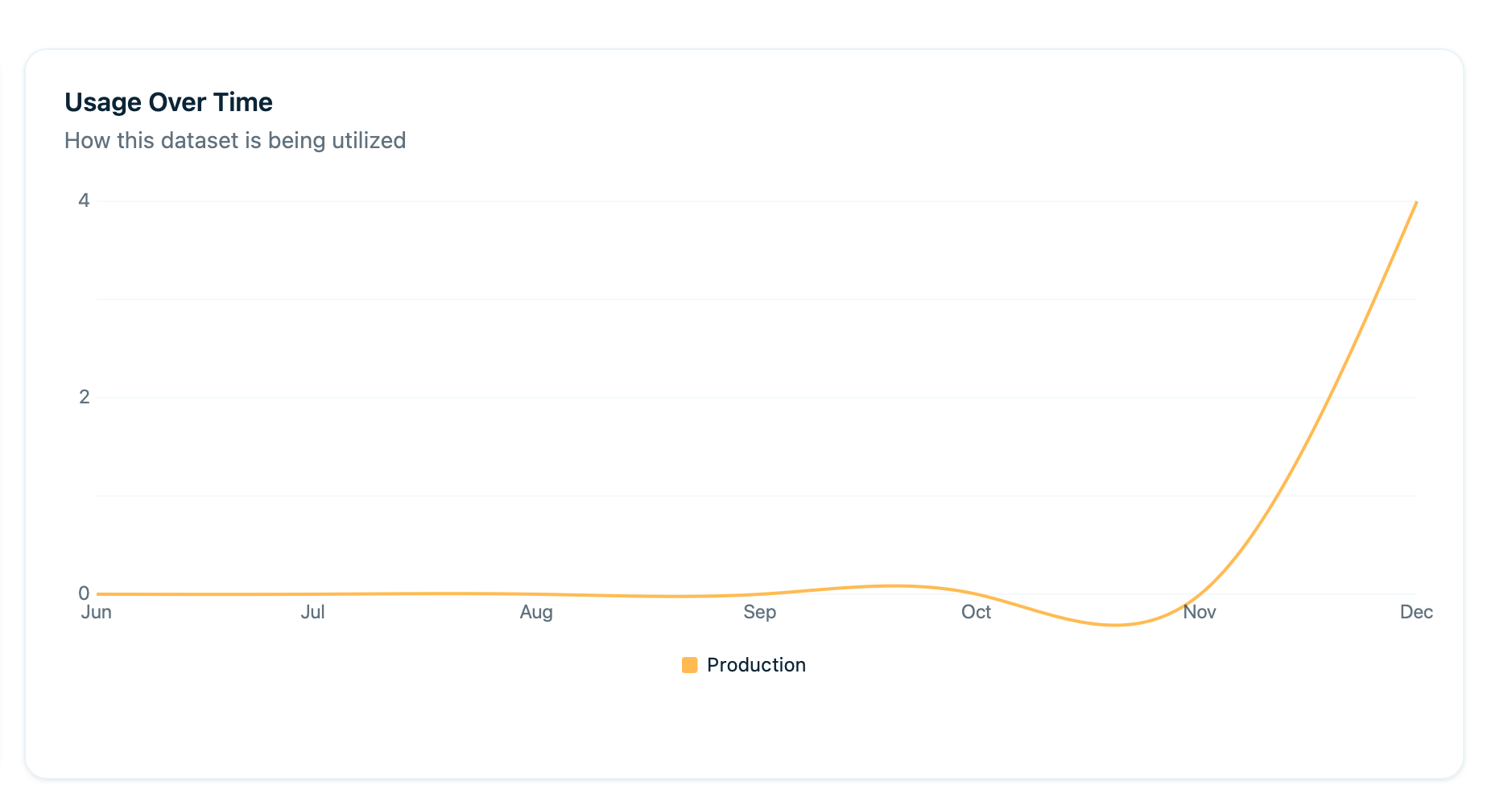
| Trend Type | What It Means |
|---|---|
| Growth Trends | Increasing usage as more queries come in |
| Declining Trends | Dataset becoming less relevant over time |
| Usage Spikes | Sudden interest in this topic or content area |
| Seasonal Patterns | Certain times of year show predictable patterns |
Quality Indicators Coming Soon
User Feedback Correlation
How users rate traces that used documents from this dataset:| Metric | Description |
|---|---|
| Thumbs up count | Positive feedback on traces using this dataset |
| Thumbs down count | Negative feedback |
| Satisfaction rate | Percentage positive |
Coverage Score
What percentage of queries in your traces find relevant documents (relevance > 0.7) from this dataset.| Coverage Level | Percentage | Meaning |
|---|---|---|
| High | >70% | Dataset answers most questions in its domain |
| Medium | 40-70% | Some gaps exist |
| Low | <40% | Significant gaps, many queries unanswered |
Comparing Datasets
View multiple datasets side-by-side to make informed decisions about where to focus your efforts.| Comparison Metric | What It Reveals |
|---|---|
| Usage Rates | Which datasets are most utilized by your AI system |
| Average Relevance | Which have best quality and strongest semantic matches |
| User Satisfaction | Which lead to good responses and positive feedback |
| Growth Trends | Which are growing or declining in importance |
Use comparison view to:
- Prioritize which datasets to improve
- Allocate resources (focus on high-usage, low-quality datasets)
- Identify which datasets can be archived or removed
Use Cases
Identify Low-Quality Datasets
Goal: Find datasets that need improvement.Sort by Average Relevance
Sort datasets by Average Relevance (low to high) to surface the lowest quality datasets
Result: Higher overall retrieval quality across your system.
Prioritize Dataset Updates
Goal: Focus updates on high-impact datasets.Result: Maximum impact from limited resources.
Find Coverage Gaps
Goal: Discover topics where you need more content.Identify Low Coverage Datasets
Look at datasets with low coverage scores to find areas with content gaps
Analyze Failed Retrievals
Check traces that found no relevant documents and group by topic/query type
Result: Better coverage, fewer unanswered queries.
Measure Dataset Improvement
Goal: Track progress after improving a dataset.Record Baseline Metrics
Document current metrics: usage rate, average relevance, and user satisfaction
Result: Data-driven proof of improvement.
Retire Unused Datasets
Goal: Clean up datasets no one uses.Result: Faster retrievals, reduced storage costs.
Dataset Health Score
Arcbeam calculates an overall health score for each dataset based on multiple factors:Usage Rate
Higher is better - more documents being retrieved
Average Relevance
Higher is better - stronger semantic matches
User Satisfaction
Higher is better - positive user feedback
Coverage
Higher is better - fewer gaps in content
Recency of Updates
More recent is better - fresh content
| Score | Health |
|---|---|
| 80-100 | Excellent - Well-maintained, high-quality dataset |
| 60-79 | Good - Solid dataset, minor improvements possible |
| 40-59 | Fair - Needs attention, several issues |
| < 40 | Poor - Major issues, requires immediate work |
Use health score to:
- Quickly assess all datasets at a glance
- Prioritize which datasets need work
- Track improvements over time
Setting Goals
Set improvement targets for your datasets to drive measurable progress.Example Goals
Product Documentation Dataset
Current State:
- 42% usage rate
- 0.68 avg relevance
- 60% usage rate
- 0.75 avg relevance
- Update top 20 docs
- Remove 15 unused docs
- Re-embed all documents
Support Articles Dataset
Current State:
- 35% user satisfaction
- 70% user satisfaction
- Rewrite top 10 most-used articles
- Add 20 new articles for gaps
Best Practices
Review Dataset Health Monthly
Set a recurring task to monitor and improve your datasets.| Task | Description |
|---|---|
| Check health scores | Review health scores for all datasets |
| Investigate drops | Look into any scores that decreased |
| Celebrate improvements | Acknowledge progress and wins |
Focus on High-Usage Datasets First
Limited time? Prioritize based on this decision matrix:| Usage Level | Quality Level | Action Priority |
|---|---|---|
| High | Low | Fix these first - maximum impact |
| High | High | Maintain current quality |
| Low | Low | Archive or improve later |
| Low | High | Monitor for future relevance |
Track Metrics Over Time
Create a spreadsheet to monitor trends and patterns.| What to Track | Why It Matters |
|---|---|
| Record key metrics monthly | Establish baseline and track progress |
| Track trends (improving, stable, declining) | Identify which datasets need attention |
| Identify seasonal patterns | Plan for predictable usage spikes |
Correlate with Business Goals
Align dataset priorities with business needs for maximum value.| Business Situation | Dataset Focus |
|---|---|
| Launching new product | Ensure product docs dataset is excellent |
| Customer support issues | Focus on support articles dataset |
| Onboarding problems | Improve getting-started dataset |
| Feature adoption low | Enhance feature documentation dataset |
Re-embed Periodically
Every 6-12 months, refresh your embeddings to maintain quality.| Action | Benefit |
|---|---|
| Re-embed datasets with latest embedding models | Newer models often improve retrieval quality |
| Track if average relevance increases | Measure ROI of re-embedding effort |
| Compare before/after metrics | Validate improvement and inform future decisions |
Next Steps
Document Usage
Drill down into individual documents
Data Lineage
Track which source files are most valuable
Add Data Sources
Keep datasets up to date
Debugging RAG
Use dataset metrics to improve RAG