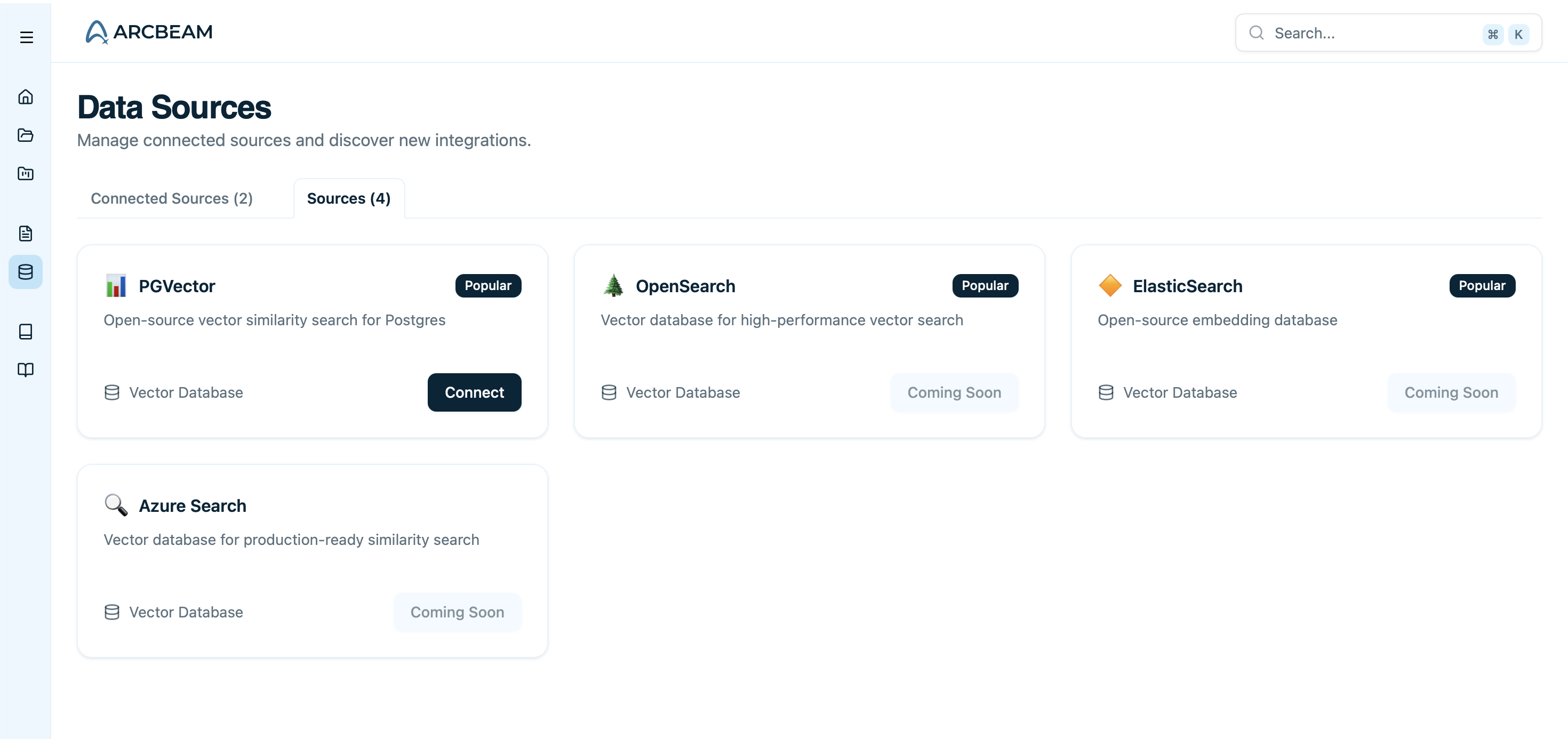
Why Connect Data Sources?
When you only see traces without data sources, you know your AI system produced an answer but you don’t know where it came from. Was it hallucinating? Did it retrieve the right documents? Which parts of your knowledge base are actually being used? With data sources connected, every trace shows:Document Attribution
Which specific documents were retrieved and their exact content
Usage Analytics
How often each document is used across all queries
Quality Insights
Which documents need updating or improvement
Actionable Data
Turn observability into concrete improvements
How It Works
Map your schema
Type which fields contain your document content, IDs, and metadata.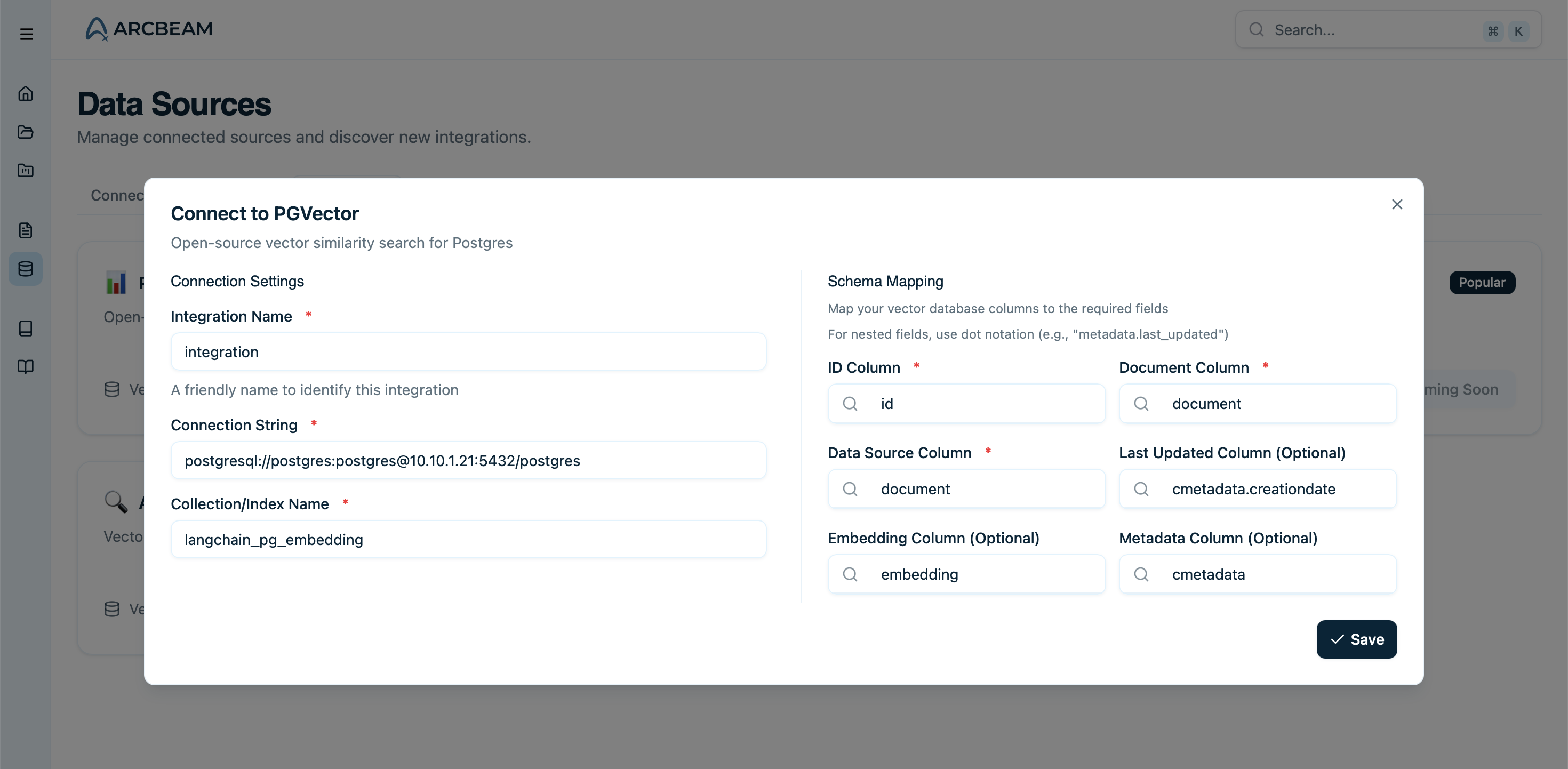
For nested columns type them out with a
. in between each level.Example: If the field you want to reference is col3 in {'col1' : {'col2': {'col3': 'value'}}}, then type in col1.col2.col3What Gets Synced
Arcbeam syncs metadata about your documents, not the documents themselves.
| Data Type | Synced? | Description |
|---|---|---|
| Document IDs | ✓ Yes | To match retrieved docs in traces |
| Source attribution | ✓ Yes | Which file/URL each document came from |
| Basic metadata | ✓ Yes | Timestamps, document names, etc. |
| Document content | ✓ Yes | Text content of documents (stays in your DB, referenced in traces) |
| Vector embeddings | ✗ Never | Your are never synced |
| Unmapped fields | ✗ Never | Only the metadata fields you explicitly specify are copied |
The actual document content stays in your vector database. Arcbeam only stores what’s needed to show you which documents were used in each trace.
Supported Vector Databases
pgvector
PostgreSQL with pgvector extension (fully supported)
Coming Soon
Pinecone, Weaviate, Chroma, and others
Privacy and Security
What Data is Accessed
What Data is Accessed
Arcbeam only reads the fields you explicitly map:
| Field Type | Accessed? | Description |
|---|---|---|
| Document IDs | ✓ Yes | Required to match documents in traces |
| Document content (text) | ✓ Yes | Document text content for display |
| Source attribution fields | ✓ Yes | Track which file/URL documents came from |
| Metadata fields | ✓ Optional | Only fields you explicitly map in configuration |
| Timestamp fields | ✓ Optional | Only if you configure last updated tracking |
| Vector embeddings | ✗ Never | Your embeddings are never accessed or synced |
| Unmapped fields | ✗ Never | Only explicitly mapped fields are read |
Connection Security
Connection Security
- Connection strings are encrypted at rest
- Database credentials are never logged or exposed
- All connections use SSL/TLS when available
- Read-only access is recommended
Self-Hosted Option
Self-Hosted Option
If your data can’t leave your infrastructure:
- Run Arcbeam in your own VPC
- Keep all data within your network
- Full control over data storage and access
When to Connect Data Sources
| Use Case | Connect Data Sources? | Why |
|---|---|---|
| Using | ✓ Yes | Track which documents are retrieved and their impact |
| Track which documents are most useful | ✓ Yes | See usage analytics and document performance |
| Debug why certain answers were given | ✓ Yes | Trace answers back to source documents |
| Measure knowledge base quality | ✓ Yes | Identify gaps and improvement opportunities |
| Only using direct LLM calls (no retrieval) | ✗ Skip | No document retrieval to track |
| Just want to track costs and errors | ✗ Skip | Traces alone provide this information |
| Using function calling without RAG | ✗ Skip | No vector database retrieval involved |
Quick Example
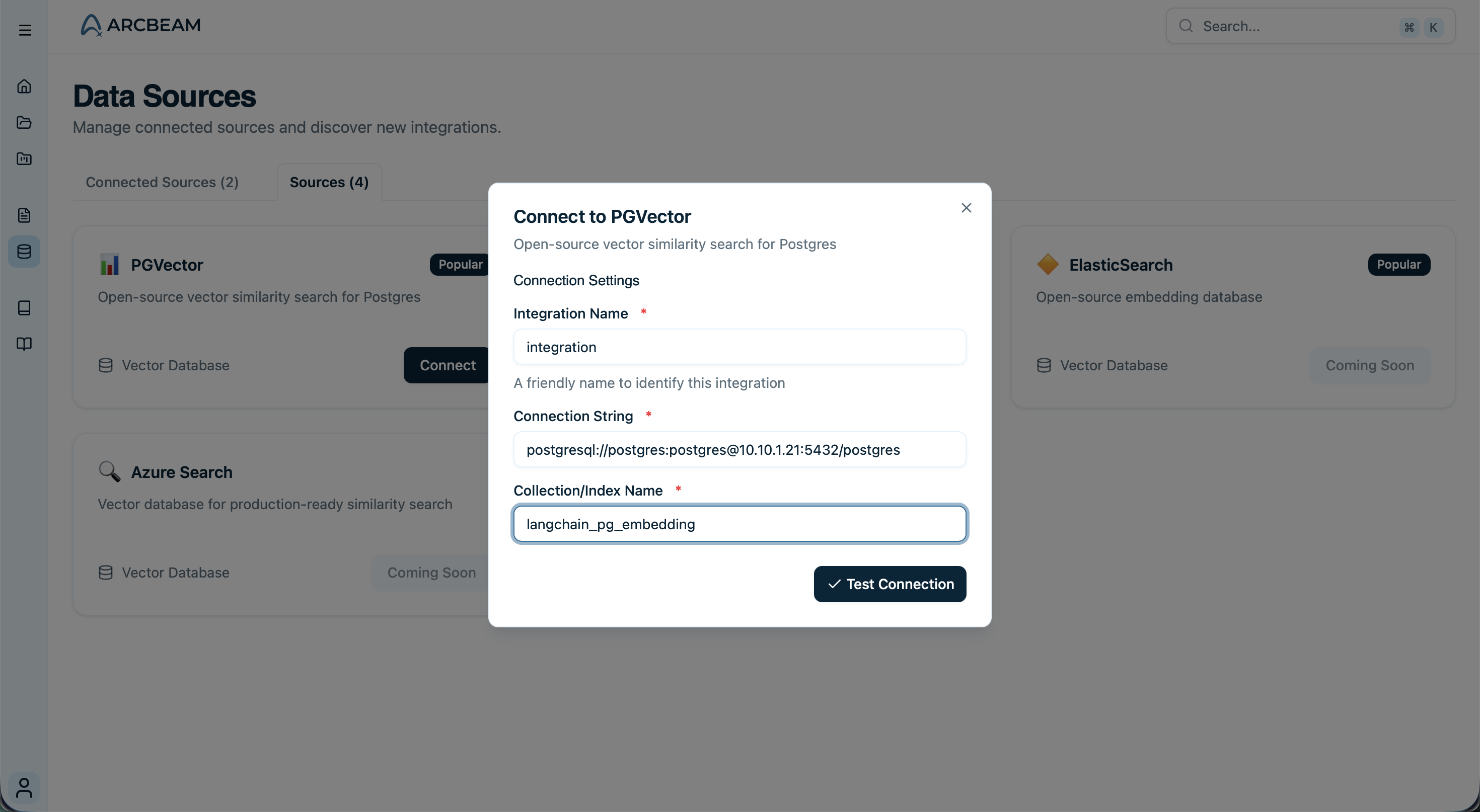
Here’s what connecting a pgvector database looks like: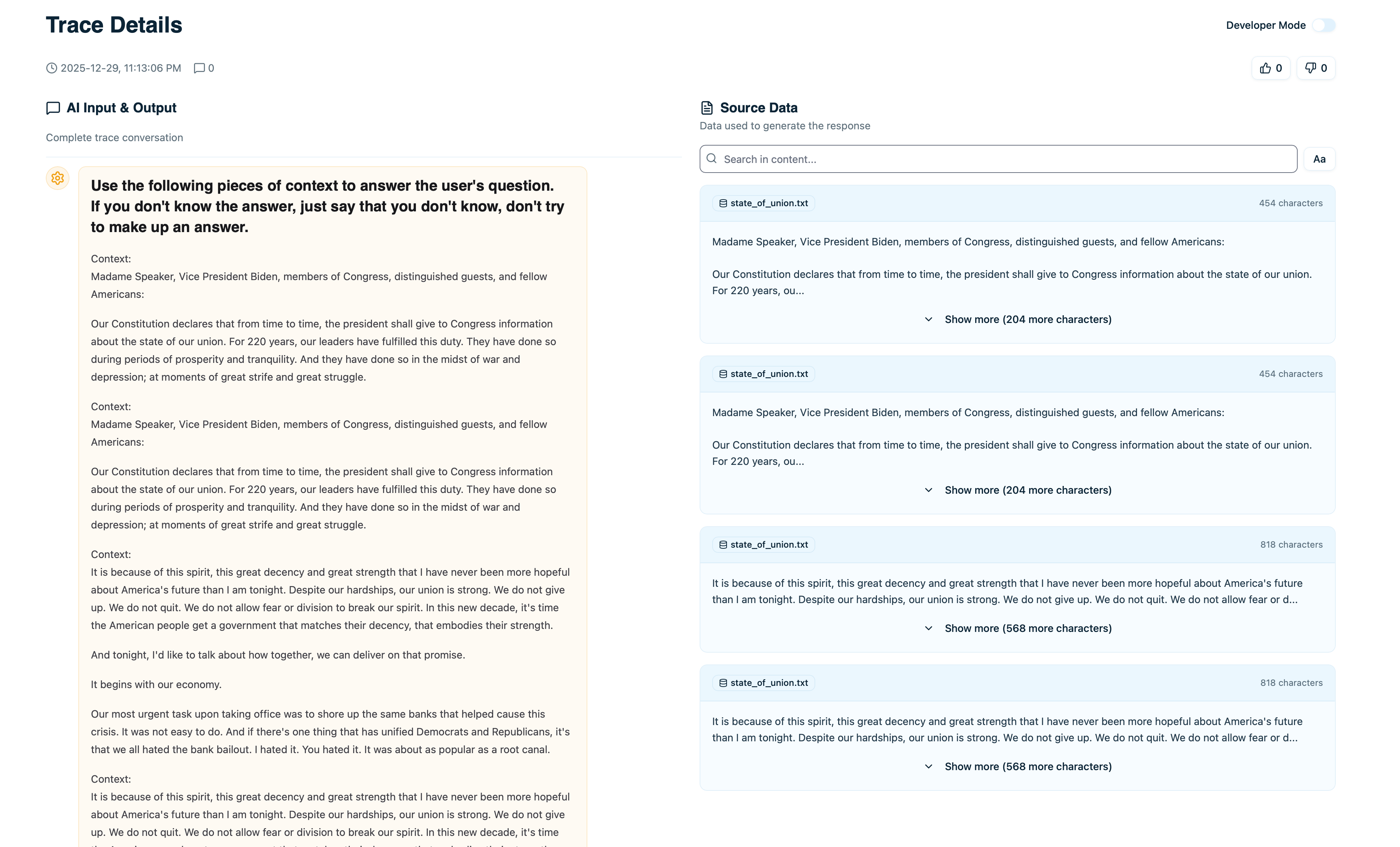
What You Can Do With Connected Data
Track Document Usage
See which documents are retrieved most often, which are never used, and which ones lead to good vs bad responses.
Debug RAG Pipelines
When a trace shows wrong information, see exactly which documents were retrieved and whether they contained the right content.
Measure Knowledge Base Quality
Find gaps in your knowledge base by seeing which queries don’t retrieve useful documents.
Improve with User Feedback
When users give thumbs down, see which documents were involved and update them accordingly.
Next Steps
Connect pgvector
Step-by-step guide to connecting a pgvector database
Data Lineage
Understand how data flows through your system
View Retrieved Documents
Explore retrieved documents in traces
Track Document Usage
Analyze which documents are being used
Common Questions
Does this slow down my database?
Does this slow down my database?
No. Syncing is a one-time operation that reads metadata. It doesn’t run queries during normal operation. Your application’s vector database queries are completely separate.
What if my schema changes?
What if my schema changes?
Update the schema mapping in Arcbeam, then trigger a re-sync. Arcbeam will refresh the metadata.
Can I connect multiple databases?
Can I connect multiple databases?
Yes. You can connect multiple vector databases or different tables/indices within the same database. Each becomes a separate dataset in Arcbeam.
Do I need read-write access?
Do I need read-write access?
No. Arcbeam only needs read access to your vector database. Using a read-only user is recommended for security.
What if I'm using multiple vector databases?
What if I'm using multiple vector databases?
Connect each one separately. Arcbeam will track documents across all of them and show you which database was used for each retrieval.